While recent text-to-video (T2V) diffusion models have achieved impressive quality and prompt
alignment, they often produce low-diversity outputs when sampling multiple videos from a single text
prompt. We tackle this challenge by formulating it as a set-level policy optimization problem,
with the goal of training a policy that can cover the diverse range of plausible outcomes for a
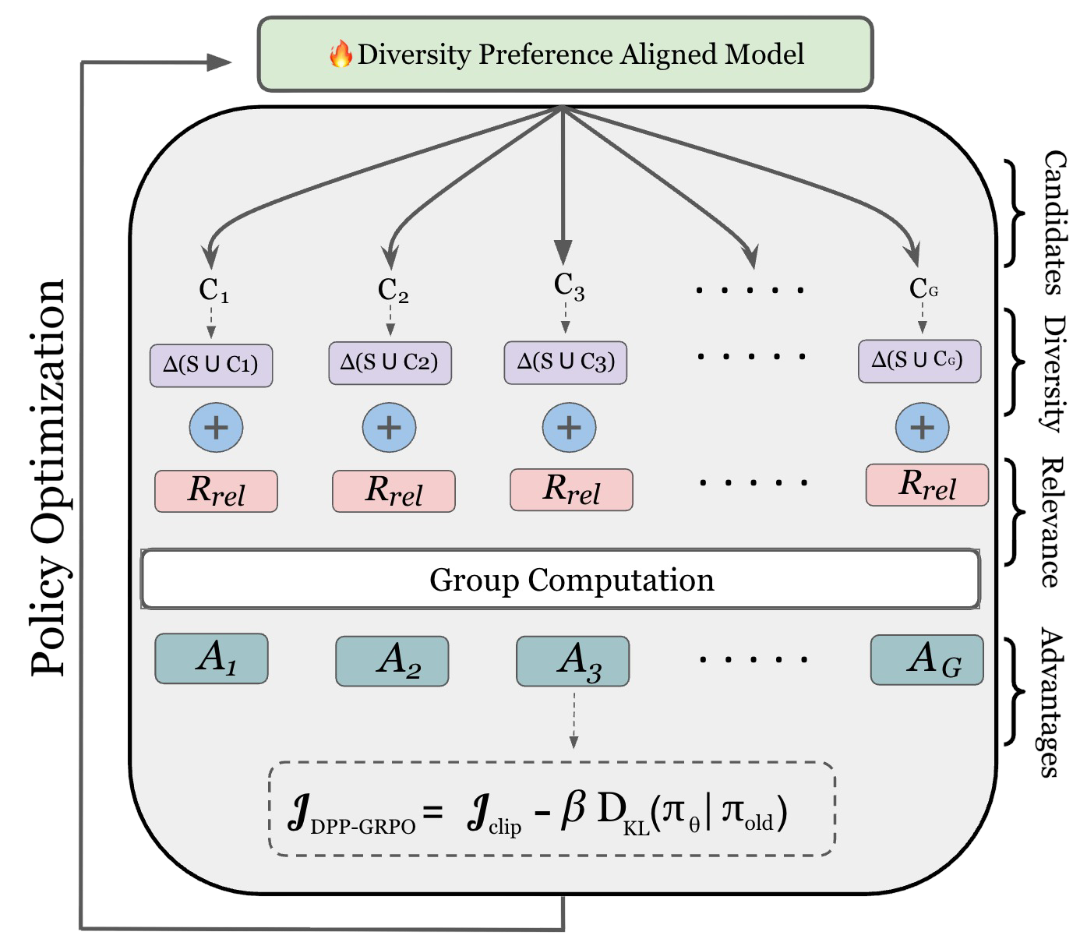
given prompt. To address this, we introduce DPP-GRPO, a novel framework for diverse
video generation that combines Determinantal Point Processes (DPPs) and Group Relative Policy
Optimization (GRPO) theories to enforce explicit reward on diverse generations. Our objective
turns diversity into an explicit signal by imposing diminishing returns on redundant samples
(via DPP) while supplies groupwise feedback over candidate sets (via GRPO). Our framework is
plug-and-play and model-agnostic, and encourages diverse generations across visual appearance,
camera motions, and scene structure without sacrificing prompt fidelity or perceptual quality.
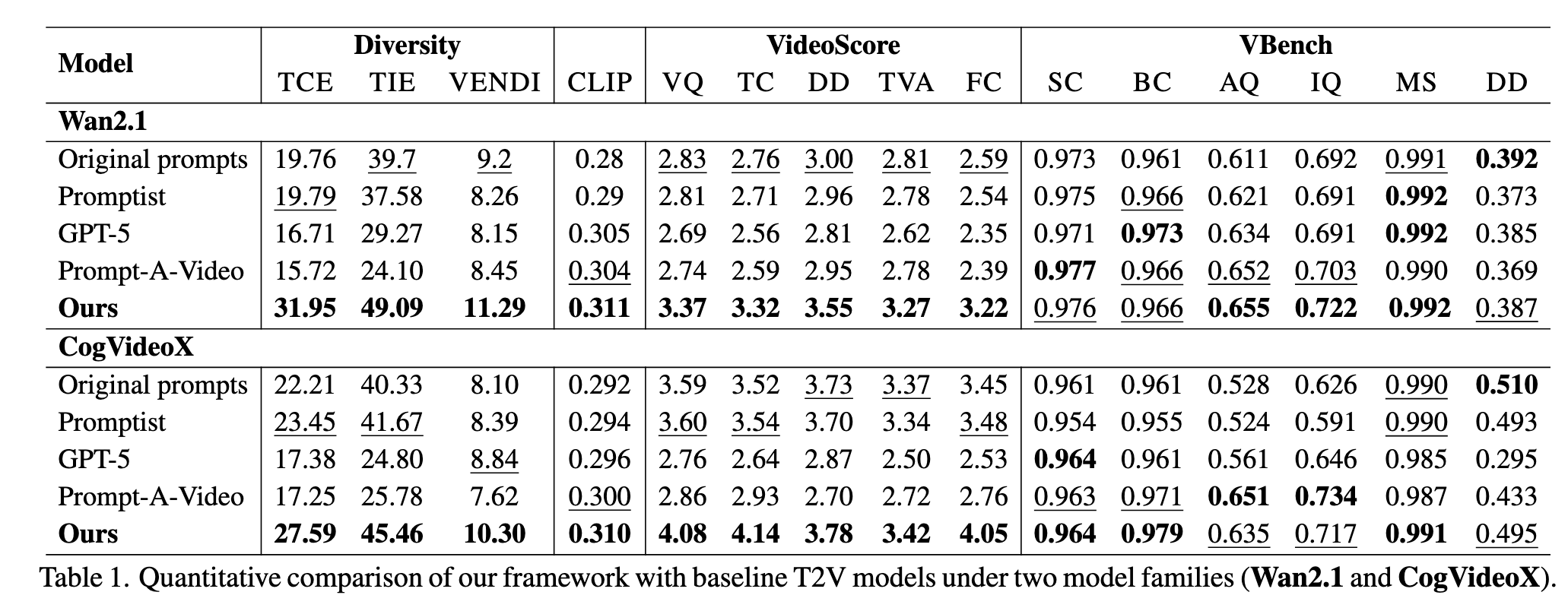
We implement our method on WAN and CogVideoX, and show that our method consistently improves
video diversity on state-of-the-art benchmarks such as VBench, VideoScore, and human preference
studies. Moreover, we release our code and a new benchmark dataset of 30,000 diverse prompts to
support future research.